Requirements: Nitro Decentralized Sequencing Requirements
|
Contents |
This page describes modifications which can be made to the Arbitrum Nitro integration in order to support Espresso-based decentralized sequencing. The purpose of this is to
In a typical Nitro rollup, a single permissioned party has the power to make blocks for the rollup. By decentralized sequencing, we mean that this power is vested in different parties for different rollup blocks. These parties can be drawn from a permissioned or permissionless set.
A decentralized sequencing protocol relies on some kind of coordination layer to define a single canonical sequence of rollup blocks based on the output of each individual sequencer. In this design, the coordination layer is Espresso. Due to Espresso’s strong non-equivocation guarantees, this coordination layer also provides finality at the same time.
A decentralized sequencing protocol also relies on some kind of election mechanism to determine which sequencer is eligible to produce rollup blocks at any given time. This design delegates sequencer election to a smart contract with an abstract interface, so that many different types of election policies can be chosen.
We ensure that each sequencer is able to track the rollup state (which may be a function of the outputs of the other sequencers) well enough that it can implement stateful sequencing logic. It is even possible that this can go beyond the default first-come-first-serve ordering policy to implement more complex sequencing strategies, if desired.
The parties involved in implementing this protocol are:
One or more sequencers. These are nodes which desire to build blocks for a particular Nitro rollup and which have the state and intelligence required to build well-formed Nitro blocks.
A sequencer manager contract deployed on the base layer. This contract determines the set of sequencers (which may be permissioned or not) and determines which sequencer is eligible to build Nitro blocks at any given time.
Espresso, which acts as a coordination and finality layer.
Other Nitro nodes and contracts, which fulfill the same roles in the system as they normally would in the centralized sequencing case.
And they interact as follows:
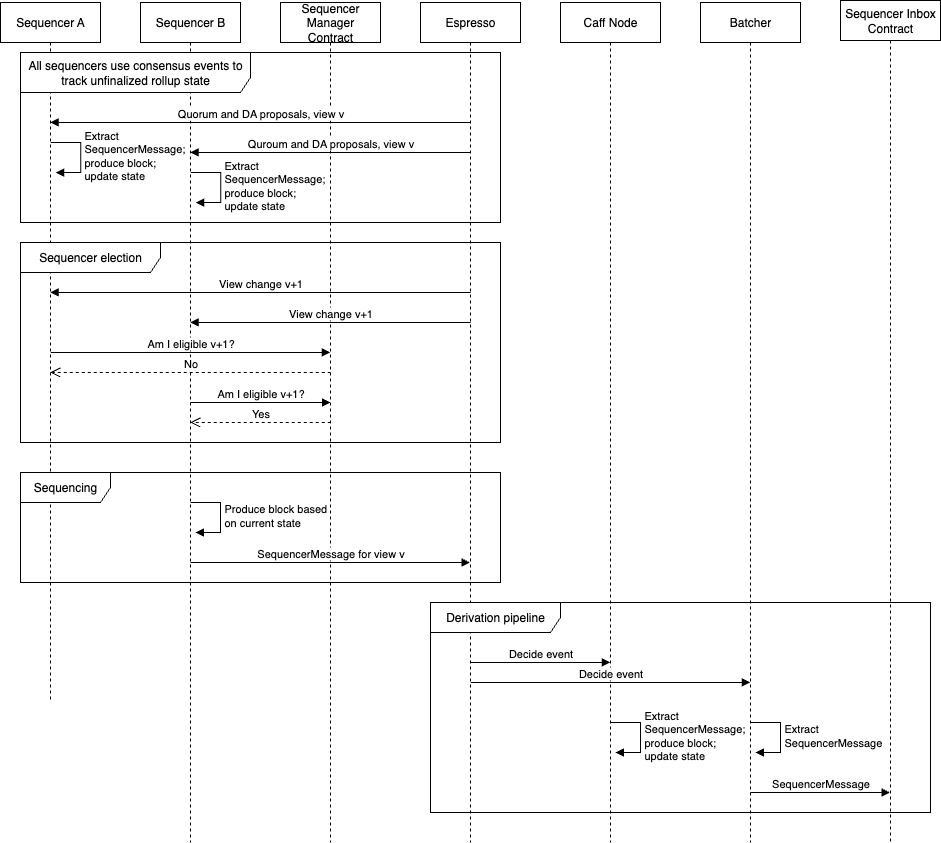
Summarizing the design illustrated here:
All sequencers, whether they are currently elected or not, keep track of the state of the rollup corresponding to all not-yet-decided Espresso views. See State Tracking.
When Espresso enters a new view, all sequencers use the sequencer manager contract to find out if they are eligible to sequence for that view. Exactly one of them should be. See Sequencer Election.
The eligible sequencer uses its current state to decide which transactions it wants to include in the next rollup block, using the exact same logic that the existing Nitro sequencer would use. It uses these transactions to produce a block and a corresponding sequencer message, signs this message, and sends the result to Espresso, exactly as the batcher would do in the centralized sequencing case.
Whenever Espresso finalizes a block, all downstream nodes (e.g. the Nitro batcher and any caffeinated nodes that are listening) convert the block to a Nitro message and then handle the message as they normally would. The only changes are to the Nitro Espresso streamer , discussed in further detail below.
Of note, the sequencers are no longer required to publish a sequencer feed. The batcher, which normally reads unsafe blocks from the sequencer and finalizes them on Espresso and the L1, now reads finalized blocks directly from Espresso, which is serving alongside the sequencer manager contract to provide a canonical ordering among the multiple sequencers. If desired, though, any node which is deriving the rollup’s block stream can choose to publish a stream. This could be a caffeinated node or a sequencer node running the caffeinated components to derive the finalized rollup blocks from Espresso.
Each sequencer must track the states of the Nitro rollup corresponding to each proposed, unfinalized Espresso view. This is because when the sequencer is elected to build a rollup block for Espresso view v, the parent view (usually but not always v − 1) will not yet have been finalized. The rollup state is needed in order to execute the sequencer logic for deciding which transactions to include, which is stateful in that it should exclude transactions which are invalid (e.g. exceed the gas limit), and may additionally implement some stateful Intelligent Sequencers policy.
The challenge is that, due to pipelining in HotShot, there are multiple outstanding Espresso views at any given time, and we don’t know which ones will or will not finalize until we get three consecutive views that extend the same ancestor. To make matters worse, while HotShot as a whole never equivocates, individual proposers may equivocate and propose multiple conflicting blocks in the same view. We don’t know which, if any, of these will be extended until we see a later view referencing an earlier proposal by hash.
In the worst case, with network asynchrony as well as equivocating proposers, we may have a tree of unfinalized proposals, only one branch of which will eventually finalize, but we must keep track of the rollup state corresponding not only to each branch, but to each internal node as well, since further branching is always possible.
Each node in this tree is uniquely identified by the pair of a view v and a proposal hash h, as shown:
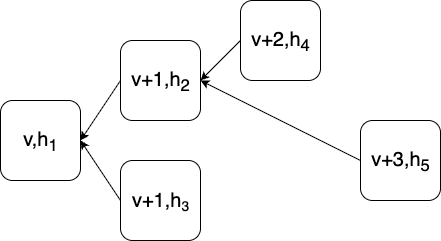
In the picture pathological situation, only view v is decided (because there is a chain of three consecutive views extending from it, v through v + 2). v + 1 will likely finalize with hash h2, but it might not do so if further branching off v occurs. While the proposer for view v + 1 has equivocated and also proposed something with hash h3, this branch will no longer be extended, as the network has formed consensus on h2 in view v + 1. Finally, either v + 2 or v + 3 could finalize, but not both, and it is possible that neither will finalize if further branching off v + 1 occurs. Depending on the next leader’s view of the network, a sequencer may be called upon to build a rollup block which extends any of these proposed views.
Thus, we need to be able to call up, fairly quickly, the rollup state corresponding to any of these proposals in order to build off it. Similarly, any sequencer (eligible or not) may at any time receive proposals from a new view that builds of any of these earlier proposals. In order to compute the new rollup state corresponding to the new proposals, we need to be able to call up the state for whatever its parent is.
Unfortunately, the Nitro database is not remotely designed to efficiently keep track of multiple states that fork in this way. Storing each state directly would require multiples of the storage space of a normal node, and would require us to make many expensive copies of the database, since updates are generally destructive. Instead, we will only store one full rollup state at a time (as the database is already designed to do), but we will store just enough additional information to (fairly quickly) transform the stored state into any state within the undecided tree structure.
Note:
In the common case, without network asynchrony, each view simply builds off the previous view, and the tree structure degenerates to a list. In this scenario, the solution we describe here always stores the tip of this list in the database, so we never need to do this transformation to a different state.
We add to the database a new key-value store called the proposal store. The keys are proposal identifiers – pairs of view number and proposal hash – and for each one we store:
The Nitro block derived from the corresponding HotShot proposal
The parent proposal ID
The proposal store represents the undecided tree via the parent references. We also keep track of the proposal ID p = (v,h) corresponding to the state which is currently represented in full in the database.
When we are called upon to extend a given state, or when we receive a proposal and need to apply it to a certain state in order to derive a new state, we can transform the database from representing proposal p to representing any other proposal p′ in the undecided view tree as follows:
At worst, this process should take us back to the last decided view. In the common case, it might not change anything at all (i.e. p′ = p) in which case we can teriminate early.
This procedure should be fairly efficient. The STF is designed to be extremely fast (a matter of milliseconds to apply each block). In virtually all cases, HotShot does not make extremely long chains of undecided views, so we only need to run the STF a small handful of times. And the reorging process needs to be at least somewhat efficient, as a reorg is something that can happen in the wild (although it is rare). Given that the occurrence of HotShot forking is also rare in practice, this should be acceptably performant.
The above procedure for transforming our database from one undecided state to another can fail due to necessary proposals being missing from the proposal store. This is possible, for example, if we never received the proposal for a particular view on the HotShot event stream (due to network issues e.g.), so we don’t know the Nitro block which is derived from that view.
This should be rare and only occur when there are problems with HotShot or the underlying network, so in this case we can fall back to something simple like proposing an empty block. Eventually, all the necessary information will propagate to all nodes (at the very least, HotShot guarantees that all decided blocks will fully propagate) and whoever is sequencer at that time can resume building non-trivial blocks.
Election of sequencers is managed by a smart contract deployed on the base layer. Each sequencer is eligible to produce Nitro blocks for (at least) one entire Espresso view. There is only one eligible sequencer at any given time.1 1Technically, with Espresso providing a single canonical ordering of transactions across multiple submitters, we could generalize this to allow multiple simultaneous sequencers. However, it would become difficult or impossible for any given sequencer to know what is sequenced before them, and thus what state they are building off of, until after Espresso completes a view. Thus, this compromises smart sequencing. For simplicity and UX, then, we restrict the design to permit a single eligible sequencer in any given Espresso view. The specific policy for electing sequencers is left up to the rollup owner, who is responsible for deploying a sequencer election contract that implements the following interface:
1 interface ISequencerElection { 2 function getEligibleSequencer(uint64 viewNumber) external view returns (address); 3 }
The abstract interface consists only of the function used by sequencers and the Espresso streamer to determine eligibility in a given view. We assume concrete implementations will have additional functions for registering and unregistering potential sequencers. However, we allow the interfaces of these functions to differ for different implementations. It is reasonable to assume that a sequencer registering for a specific sequencing policy has knowledge of the details of the policy and thus is able to call the non-interface functions required to register.
Technically, there is more to finding the eligible sequencer than simply
calling getEligibleSequencer. The function must always be invoked at a specific,
finalized, L1 block number. This is because the mapping of Espresso views
to sequencer addresses must be deterministic, but changes to the contract
state (e.g. new sequencer registrations) could cause getEligibleSequencer to
return different results for the same view when invoked at different base layer
states.
Thus, the canonical mapping from Espresso views to unique eligible sequencers
is, for any Espresso view v and rollup block b, the result of invoking
getEligibleSequencer(v) at the base layer block number referenced by rollup block
b − 1. Since getEligibleSequencer is a pure function with respect to a particular base
layer state, and the contents of rollup block b − 1 (including the base layer block
number it references) are fully determined by Espresso, which is strongly resistant to
equivocation, this mapping overall behaves as a pure function, with the
acceptable caveat that the sequencer for view v is unknown until the parent view
completes.
The default sequencing policy will be a simple permissionless round robin. Anybody can register or unregister as a sequencer at any given time. The sequencer for view v is taken by indexing v slots into the list of registered sequencers as of the parent view.
The implementation consists of a list of registered sequencers (i.e. address)
maintained in contract storage. The list should efficiently support Append and Remove
operations. It should also support Index and Length operations; however, these are
only used by the read-only function getCurrentSequencer, which is meant to be
simulated offchain, not executed onchain. Thus efficiency in terms of gas
consumption is less important for these operations, so long as they can be
simulated offchain in a reasonable amount of time for a reasonable length
list.
A linked list may satisfy these requirements if the number of registered sequencers is not too high (since indexing can be slow). A B-Tree supports all of the operations, including the offchain functions, efficiently, and is often used for similar use cases in databases with slow, inefficient storage. This makes it a good choice for the case of expensive-to-access contract storage.
Note that a simple array is not sufficient, as it does not efficiently support Remove;
all entries following the removed entry must be copied to an adjacent storage
location, which can cost a tremendous amount of gas.
The contract allows any sequencer to register and unregister at any time. It also has an owner who can unilaterally unregister any sequencer:
1 contract HotshotNitroSequencerManager: ISequencerElection { 2 address owner; 3 ListOfAddresses sequencers; 4 5 constructor { 6 owner = msg.sender; 7 InitializeEmpty(sequencers); 8 } 9 10 // Anyone can register 11 function register() external { 12 Append(sequencers, msg.sender); 13 } 14 15 // Anyone can unregister themselves, or the owner can unregister anyone. 16 function removeSequencer(uint64 index) external { 17 require(msg.sender == owner || msg.sender == Index(sequencers, index)); 18 Remove(sequencers, index); 19 } 20 21 function getCurrentSequencer(uint64 viewNumber) external view returns (address) { 22 // Choose the sequencer based on round robin 23 uint256 sequencerIndex = viewNumber % Length(sequencers); 24 return Index(sequencers, sequencerIndex); 25 } 26 }
This decentralized sequencing mechanism is compatible with any implementation of the sequencing logic itself, including the default first-come-first-serve sequencer that comes with the Nitro stack, but also potentially with alternative implementations that use different ordering policies or optimizations. Different sequencers that are elected at different times may even use different policies.
However, any sequencer may require some slight modifications to properly integrate with Espresso:
The sequencer must gracefully handle execution state changing spontaneously under it. This can happen when Espresso switches to a different undecided fork of the state, as in State Tracking, or when a message is added to the block stream by a sequencer other than this one.
The default Nitro sequencer already has this property, as it is designed to
handle reorgs of the state (via the resequenceReorgedMessages method of the
execution engine) as well as messages produced asynchronously by other
sequencers (for example, even in the standard Nitro stack, the regular
sequencer and the delayed message sequencer are treated as separate
sequencers that each produce blocks asynchronously from one another).
The sequencer’s nonce cache should prevent it from including transactions
from its mempool which were already included in an earlier message by a
different sequencer.
The sequencer must broadcast a signed feed consisting of all messages it produces. This can be hooked up to the Sequencer Relayer component which is standard for any sequencing implementation and takes care of forwarding messages produced by a custom sequencer to Espresso.
The relayer is a new component responsible for integrating an existing Nitro sequencer, which of course knows nothing of Espresso, with the Espresso-based decentralized sequencing protocol. The relayer runs in the same process as the sequencer and subscribes to messages produced by the sequencer feed. It uses the signatures on the messages to filter for only those produced by its own sequencer. It tracks the Espresso view number and sequencer eligibility in the same way that the sequencer itself does, and whenever it receives a message from its own sequencer during or just before a view where that sequencer is eligible, it sends that message to Espresso, as described in the next section.
The format of transactions sent from an eligible sequencer to Espresso is identical to the format used by the Nitro batcher in the centralized-sequencing case, namely:
MessageThis data becomes the body of an Espresso transaction, with namespace taken from the chain ID of the Nitro rollup.
This ensures compatibility with the Nitro Espresso streamer , except for minor changes as noted below.
The centralized-sequencing transaction format allows multiple of these types of message to be concatenated within a single Espresso transaction, and also allows multiple Espresso transactions within a single block to contain messages for the rollup. This behavior still applies in the decentralized sequencing case. That is, while a sequencer may only be eligible for a single Espresso view, it still has the option to produce multiple Nitro messages. This allows Nitro rollups to retain their fast (e.g. 250 ms) block times even if Espresso’s view time is much slower.
Transaction submission from an eligible Nitro sequencer to Espresso is very similar to normal transaction submission. The sequencer sends its transaction to an Espresso builder. Eventually, the builder is called upon to build a block for the view in which the sequencer is eligible, and it includes that transaction in the block.
The trick here is that the sequencer must express to the builder the constraint that this transaction is only valid when included in a specific view. Normal user-submitted transactions do not have this constraint, and the builder will include them in the first view that it can. Thus, the sequencer includes the desired view number alongside the transaction when it sends it to the builder (e.g. as an extra parameter in the HTTP request). The builder stores such transactions in a separate mempool, indexed by view number. When called upon to build a block for view v, the builder will include transactions designated for view v first, before including transactions from the general mempool as blockspace allows. Once view v + 1 begins, the builder can delete un-sequenced transactions from the view v mempool.
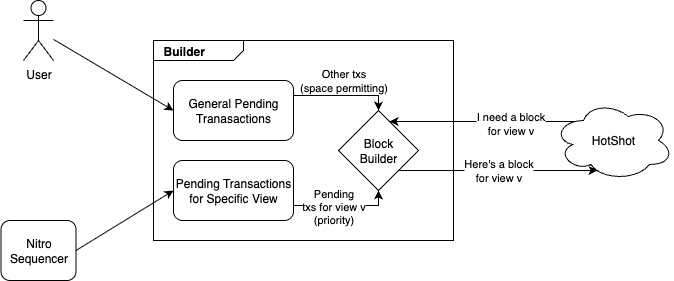
In fact, any party can submit transactions designated for a specific view, regardless of whether they are an eligible Nitro sequencer for that namespace and view or not. The builder performs no authentication; all Nitro transactions submitted by ineligible sequencers will later be filtered out by the Espresso streamer. To prevent resource exhaustion attacks, the builder may reject a request to sequence a transaction in a view which is sufficiently far in the future, rather than storing that transaction for many views.
Tech Debt:
You may be wondering why, since the Nitro sequencer already knows exactly which view their transaction should be included in, can they not submit their transaction directly to the leader of view v as a block proposal, eliminating the builder from the flow. This would be a simpler design and remove a network hop of latency, and so indeed such a design would be better than the one outlined above.
The problem is that we would still want the consensus leader to include other proposals for unrelated namespaces in the same block, and there is currently no ability for HotShot leaders to combine multiple proposals from different parties into a single block: this is explicitly the role of the builder.
The design above is preferred as it does not require changes to HotShot, but in the future should HotShot support this ”multiple proposals per block” functionality, we should revisit this design.
The delayed sequencer is responsible for detecting when new delayed messages are waiting in the inbox contract, and creating messages that increment the delayed message counter such that these messages are processed. The delayed sequencer has a power that the normal sequencer doesn’t have: it can reference, by number, a delayed message that the L1 has not yet finalized. This forces downstream nodes, like the Nitro caffeinated node , to block until the L1 finalizes the delayed message, or risk state corruption caused by potential L1 reorgs. This process can take a long time.
In the centralized sequencer case, the delayed sequencer is a part of the overall sequencer which is approved by the rollup owner, so we assume it is incentive-aligned with the rest of the rollup components, and will not intentionally do this. However, in a permissionless sequencer setting, we have to prevent a single malicious sequencer from stalling the progress of the rollup far beyond its elected sequencing slot through this mechanism, which would violate the Fault Tolerance requirement.
To this end, the sequencing of delayed messages in the decentralized setting is subject to strict rules, violation of which will cause the espresso streamer to ignore the messages entirely. The delayed sequencer component must be replaced with one that adheres to these rules.
In the Nitro stack, the delayed sequencer is an autonomous component which runs entirely in parallel with the normal sequencer and simply produces new messages whenever it is ready (i.e. whenever the L1 finalizes new blocks which contain new delayed messages). It uses a lock to coordinate its message production with that of the normal sequencer, a separate component running in the same process. This makes it straightforward to replace the delayed sequencer wholesale with one that follows stricter rules about when delayed messages can be produced, while playing the same role in the overall architecture of the sequencer node.
The replacement delayed sequencer works quite similarly to the default one.
However, instead of scanning the L1 directly for new finalized blocks, it scans
Espresso blocks waiting for the l1_finalized field of the header to increment, which
tells it not only that the referenced L1 block is finalized, but that every other node
will agree that it is finalized. This enables the delayed sequencer to safely build off
this new finalized block while maintaining compliance with the new rules for deriving
delayed messages. It can then create delayed messages for any messages which were
added to the inbox contract between the previous finalized block and the new
one.
Tech Debt:
While the replacement of the delayed sequencer is architecturally straightforward, implementing an entirely new delayed sequencer is not a trivial engineering task. Thus, the first version does not have this mechanism for enforcing the safety of delayed messages. Instead, the role of sequencing delayed messages remains permissioned, and only normal sequencing is decentralized.
This comes with a drawback: it is difficult to determine how often the permissioned delayed sequencer should come up in the rotation through registered sequencers. Not often enough, we may add significant delay to the sequencer of delayed messages, potentially even risking a force inclusion. Too often and we may be stuck with a delayed sequencer for an entire HotShot block when there are no delayed messages to sequence. The solution to this latter problem is to allow the delayed sequencer to also act as a normal sequencer during its slot. To avoid unfairly empowering this normal sequencer by having its slot come up artificially often in avoidance of the former problem, the total number of sequencers should be kept low enough that even with the natural rhythm of round robin, this special sequencer comes up often enough.
Just like the Nitro Espresso streamer in the centralized sequencer case, various components need to derive a stream of Nitro messages from a stream of HotShot blocks. This works mostly the same in the decentralized sequencer case, since in both cases, what is actually sent to Espresso is the same: a Nitro message along with a sequencer signature. The only differences are in the signature validation and the handling of delayed messages.
In the centralized sequencer case, the sequencer key – the public key against which the sequencer signature is verified – is hard-coded in the rollup config. In the decentralized sequencer case, the Espresso streamer must read the Espresso leaf to find out what view number the block was created in, and then call the sequencer manager contract to find out the eligible sequencer key for that view.
Without special handling of delayed messages, a malicious Delayed Sequencer could cause the Espresso streamer to block, potentially for a very long time, waiting for L1 finality, simply by referencing a delayed message which was included in an L1 block which has yet to finalize. This breaks the Fault Tolerance requirement. Our solution is to ignore unfinalized delayed messages; however, care is needed to do this deterministically. If we simply query the L1 to check if a given delayed message is finalized, different nodes running the streamer at different times may get different results: one queries the L1 before the delayed message has finalized and ignores it, while another queries after the message has finalized and keeps it.
To make this deterministic, we base our determination of whether a given
message is finalized on the l1_finalized field of the Espresso header that
includes it. This will always reference the same L1 block no matter when the
derivation is run, since Espresso itself is deterministic, and the L1 block it
references will always be finalized, guaranteed by the honest majority of Espresso
nodes.
The check, then, is whether the referenced message exists in the inbox contract at the block number indicated by Espresso, which is a deterministic query.