Requirements: Nitro Integration Requirements
|
Contents |
This page specifies the design of an integration of the Arbitrum Nitro rollup stack with the Espresso GCL.
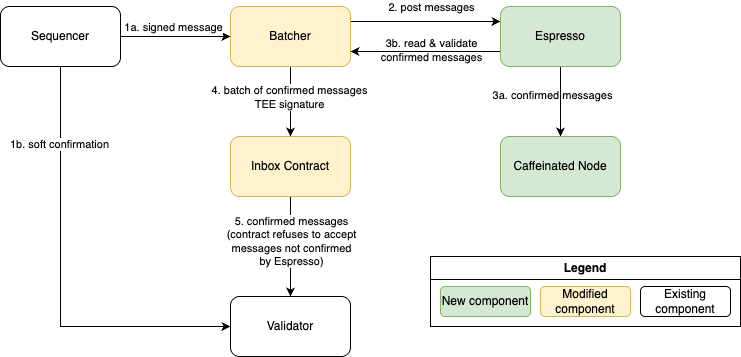
The high level idea is to forward every message from the centralized sequencer to Espresso for confirmation, and then to have a deterministic derivation of a sequence of messages from Espresso. This derivation becomes the input to the STF, ensuring that the state finalized by the rollup is derivable from Espresso, and any party who is interested (e.g. bridge protocols and exchanges) can run this same derivation to derive the rollup state ahead of time.
In order to enforce that the rollup eventually finalizes a sequence of messages that has been confirmed by Espresso, the batcher must prove to the inbox contract that it is correctly deriving the messages it is posting from Espresso, and the inbox must revert if the batcher fails to do this. This is done by running the batcher in a trusted execution environment (TEE). The batcher can thus generate an attestation which proves to the inbox that the batcher is running the appropriate code for confirming messages with Espresso. The contract then refuses to accept any batch which is not posted by such a batcher, preventing such batches from being processed by the rollup
The design of the integration is described in more detail in pages for each component.